What AI Agents Do That AI Tools Don't
Most AI tools are reactive. You open them, you ask, they answer. The value is real — but it still depends entirely on you showing up first.
AI agents are different. They don’t wait to be asked. They watch, reason, decide, and act — then loop back and do it again. Applied to customer intelligence, this changes something fundamental: instead of learning what your customers think after the fact, you can have a system that notices before you do.
This isn’t a prediction about the future. It’s already happening — quietly, in the background of companies that have started wiring agents into how they listen to customers. But the distinction between “AI tool” and “AI agent” is still poorly understood, and the gap matters more than most teams realize.
What actually makes something an “agent”
The word “agent” gets used loosely. A chatbot isn’t an agent. A recommendation engine isn’t an agent. Even a sophisticated AI feature that generates survey questions when you ask isn’t an agent — it’s a very capable tool.
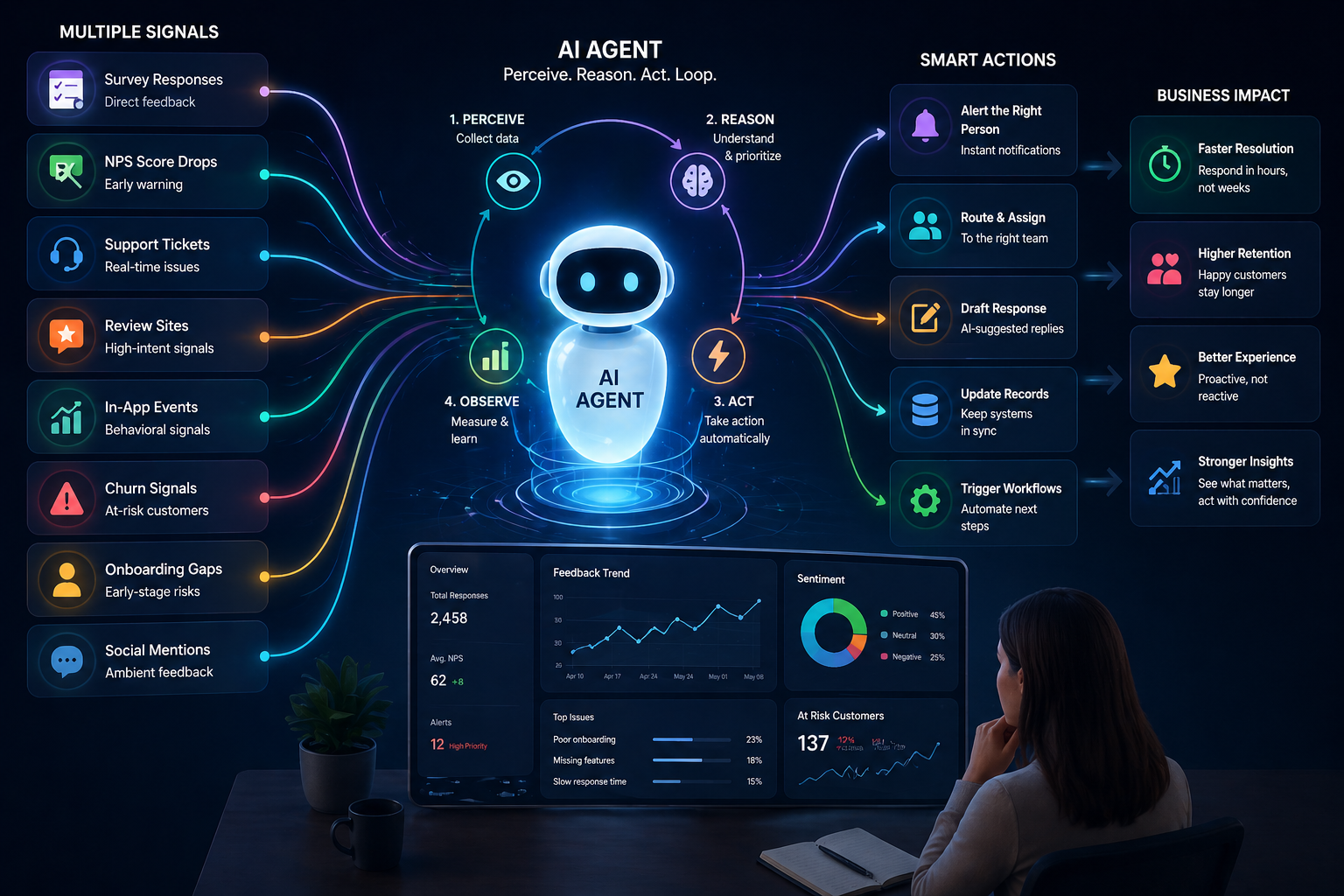
An agent is defined by a loop:
- Perceive — take in information from the environment (a survey submission, a support ticket, a drop in NPS scores, a user behavior event)
- Reason — decide what the information means and what, if anything, should happen next
- Act — do something: send an alert, route a ticket, draft a response, update a record, trigger another process
- Observe — check what happened as a result, and feed that back into the next cycle
Traditional AI tools participate in steps 1 and 2 — you give them input, they give you output. The agent completes all four steps and then repeats them, without being prompted to start the next cycle.

Gartner predicted in 2024 that by 2028, 15% of day-to-day work decisions at organizations will be made or initiated autonomously by agentic AI — not because humans are removed from the picture, but because a growing category of clear, low-stakes, high-frequency decisions is better handled by systems that can act without waiting.
The analogy that lands for non-technical audiences: the difference between a thermometer and a thermostat. A thermometer tells you the temperature when you check it. A thermostat perceives the temperature, compares it to a target, and acts — turning the heat on or off — without you asking. An AI agent is a thermostat for your business environment.
The feedback lag that nobody talks about
Here is a sequence that plays out in the overwhelming majority of companies, right now, this week:
A customer runs into a problem. They don’t send a support ticket — they tell two colleagues, leave a review on G2 or Trustpilot, and quietly start evaluating your competitor. Two weeks later, your quarterly survey goes out. Some customers respond. A few weeks after that, the team reviews the results in a meeting. A decision gets made. Weeks later, a fix ships.
The total elapsed time: six to eight weeks. The customer who had the problem? They’ve probably already churned.

Research from Bain & Company shows that customers who have a problem resolved quickly — within one to two days — are 2.5x more likely to remain customers than those who wait longer than a week. Jay Baer’s customer experience research, cited in Harvard Business Review, found that companies responding to customer issues within one hour are significantly more likely to have meaningful, recoverable conversations than those that don’t.
The survey didn’t fail here. The timeline did.
An agent doesn’t eliminate the problem, but it compresses the timeline. Instead of the signal sitting in a survey queue for two weeks before a human sees it, an agent can detect the pattern, route the alert, and initiate a response within hours of the original event — without anyone remembering to check a dashboard.
What a customer intelligence agent can actually hear
Most teams think of feedback as what comes in through surveys. Surveys are one input. An agent-powered customer intelligence system can listen to much more:

Each of these channels carries different signal at different moments:
- Survey responses are rich but infrequent — they capture considered, explicit feedback, but only from customers who participated
- NPS score drops are early warnings — a sudden shift in a segment or cohort often precedes visible churn by weeks
- Support tickets are real-time distress signals — the customer is still present and asking for help
- Review site mentions are high-intent signals — someone who writes a review (positive or negative) is expressing strong feeling
- In-app events are behavioral signals — a user who stops using a core feature is communicating something they may never say in a survey
- Churn signals (missed renewal, downgrade, deactivation) are terminal — the decision has been made; only a fast response can reverse it
- Onboarding gaps are early-stage risk indicators — a customer who skips onboarding steps often struggles later
- Social mentions are ambient signals — informal, often unfiltered, sometimes early
A traditional survey-only approach captures one spoke. An agent can synthesize signals across all of them simultaneously, weighting them by urgency, recency, and customer segment. A single detractor survey response is one data point. A detractor survey response from a customer who also filed two support tickets and skipped three onboarding steps is a pattern — and an agent can recognize it as one.
What agents are actually doing with those signals right now
This is not theoretical. Enterprises have been deploying agentic customer intelligence systems since 2023, and the results are being reported publicly.
Salesforce launched Agentforce in 2024 — a platform for deploying AI agents that can handle customer inquiries, route issues, and trigger workflows autonomously. Their early deployments reported resolution times 40–60% faster than human-only workflows for standard support patterns.
Microsoft’s Copilot agents (introduced in 2024 as part of Microsoft 365) allow companies to build agents that monitor signals across Teams, CRM records, and email — surfacing patterns in customer behavior and drafting follow-up actions for review.
Forrester’s 2024 report on AI adoption found that 63% of enterprises were piloting agentic AI — not just AI features, but autonomous systems that can initiate actions based on observed conditions.
For smaller businesses and product teams, the practical implementations are less dramatic but just as valuable:
- An agent that monitors NPS submissions in real-time and automatically creates a task in the CRM for any detractor response, tagged with the customer’s tier and tenure
- An agent that detects when a trial customer hasn’t completed onboarding within 72 hours and triggers a personalized check-in email — not a template blast, but a contextual message based on what step they got stuck on
- An agent that aggregates support tickets weekly, clusters them by theme using natural language understanding, and surfaces a ranked list of systemic issues to the product team — without anyone needing to read 200 individual tickets
The common thread in all of these: the agent collapses the distance between signal and response, without requiring a human to be the connection between them.
Where agents fall short — and why humans aren’t optional yet
The honest version of this picture includes the places where agents get it wrong.
Hallucination is real. Large language models — the reasoning layer inside most AI agents — can generate confident, plausible-sounding outputs that are factually incorrect. Research benchmarking 37 LLMs found hallucination rates above 15% in certain contexts. An agent that incorrectly classifies a customer’s issue, misroutes a high-priority escalation, or sends an inaccurate response is not just unhelpful — it can actively damage the customer relationship.
Context collapses. An agent reasoning from structured data — survey scores, ticket categories, behavioral events — often misses the human context that would change the response. A low NPS score from a long-term enterprise customer with a known ongoing contract negotiation means something very different from a low NPS score from a new user who just signed up. Agents that don’t have access to rich CRM context, or can’t weight it correctly, will make wrong calls.
High-stakes decisions need humans. The Gartner prediction is notable for what it doesn’t say: it says 15% of day-to-day work decisions will be autonomous — not 50%, not most. The decisions that carry real consequence — how to respond to an enterprise churning, what to commit to a major account, how to communicate a pricing change — those decisions still require human judgment, and handing them to an agent is a risk most businesses shouldn’t take.
The right mental model is not “agent replaces human” but “agent handles the high-frequency, clear-signal, low-stakes actions so that humans can focus on the high-stakes, ambiguous, consequential ones.”
Knowing when to let agents act — and when to stay in the loop
Not all customer signals are equal, and not all agent actions carry the same risk. The right framework isn’t binary (agent acts / human acts) — it’s a spectrum.

The most productive deployments of customer intelligence agents operate in the bottom-right quadrant first — clear signals, low stakes, high frequency. Things like: routing a support ticket to the right team, tagging a survey response with a sentiment category, sending a check-in email to a stalled trial user. The cost of a wrong action here is low; the benefit of speed and scale is high.
As you build confidence in how the agent reasons, you can gradually extend its authority into the top-right quadrant — clearer signals with higher stakes — where the agent drafts an action and a human approves it before it happens.
The top-left quadrant (ambiguous signal, high stakes) should remain human territory indefinitely. An enterprise customer with a nuanced complaint, a long-term relationship, and an active contract renewal on the table — that conversation needs judgment that agents don’t yet reliably provide.
The framework forces a useful question: for any given agent deployment, which quadrant is this operating in? Teams that skip this question tend to deploy agents too aggressively in high-stakes contexts, get burned when something goes wrong, and overcorrect by pulling agents out of low-stakes contexts where they would have been genuinely useful.
What this means for how you run customer research today
If you’re running surveys today, the practical implication isn’t “stop running surveys.” It’s: stop treating surveys as the only channel and start treating them as one input to a larger system.
A survey is a high-signal channel. When customers respond thoughtfully, the data is explicit and structured — easier to act on than inferred behavioral signals. But surveys are also periodic, respondent-selected, and slow. They tell you what a subset of your customers chose to tell you, on the day they chose to tell you.
The shift that agent-enabled teams are making is to use surveys as the anchor — the deliberate, structured, periodic measurement — while agents handle the continuous layer: monitoring behavioral signals between surveys, routing urgent issues before they become survey data, and synthesizing patterns across channels that no survey can reach.
In this model, your quarterly NPS survey becomes the checkpoint that validates or challenges what your agent has been observing. The two reinforce each other instead of being the only tool in the box.
How SurveyReflex fits in
SurveyReflex is already moving in this direction — AI-powered survey creation, AI-driven analysis of open-ended responses, and tools that surface patterns across your data rather than requiring you to read every response manually. The goal is to make the survey part of your feedback system faster, smarter, and more connected to action.
As agentic capabilities mature, the survey becomes one spoke in a larger intelligence wheel — not less important, but more powerful when it’s part of a system that’s also listening between the moments you ask.
If you’re not already running structured customer feedback cycles, that’s the foundation. Build it first. The agent layer amplifies what’s already there — it doesn’t replace the discipline of asking good questions and actually acting on the answers.
Try SurveyReflex free — pay only when you need more than 50 responses.
References
- Gartner (2024). By 2028, Agentic AI Will Autonomously Resolve 15% of Day-to-Day Work Problems.
- Salesforce Agentforce (2024). Platform overview and early deployment results.
- Forrester (2024). Predictions 2025: AI Agents Move From Pilots to Production.
- Microsoft Work Trend Index (2024). AI at Work: From Tools to Agents.
- Jay Baer / Harvard Business Review (2012). Companies That Respond to Customer Complaints in 1 Hour.
- Bain & Company. The Economics of Customer Loyalty.
- LLM Hallucination Benchmark (2024). Evaluation of 37 Large Language Models.
— The SurveyReflex Team